Navigating the Layers of Hadoop: Understanding the Framework’s Architecture

Navigating the Layers of Hadoop: Understanding the Framework’s Architecture
The story begins in the early 2000s when Google faced the challenge of processing vast amounts of data across multiple servers. They introduced Google File System (GFS) and MapReduce, laying the foundation for what would become Hadoop. In 2005, inspired by Google’s approach, Doug Cutting and Mike Cafarella embarked on a journey to create an open-source framework that would democratize Big Data. Hadoop, named after Doug’s son’s stuffed elephant, was born.
Hadoop is an open-source framework designed to store and process large datasets in a distributed computing environment. It’s often used for big data storage and analysis. Hadoop’s architecture is based on a few key components that work together to manage and process data efficiently.
Here’s an overview of the main components of Hadoop architecture:
Hadoop Distributed File System (HDFS): HDFS is the primary storage system in Hadoop. It’s designed to store vast amounts of data across a distributed cluster of commodity hardware. HDFS divides large files into smaller blocks (typically 128MB or 256MB in size) and replicates these blocks across multiple nodes in the cluster for fault tolerance. HDFS is the foundation for storing big data in Hadoop.
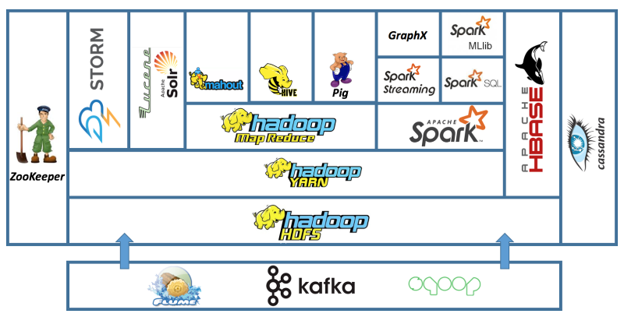
MapReduce: MapReduce is a programming model and processing engine used in Hadoop for parallel data processing. It processes data in two phases: the Map phase, which sorts and filters the data, and the Reduce phase, which aggregates and summarizes the results. MapReduce jobs are written in Java or other supported programming languages and are used for tasks like data transformation, aggregation, and analysis.
YARN (Yet Another Resource Negotiator): YARN is the resource management and job scheduling component in Hadoop. It allows multiple applications to share cluster resources efficiently. YARN decouples the resource management and job scheduling functionalities, which improves cluster utilization and allows for running a variety of applications, not just MapReduce, on the Hadoop cluster.
Hadoop Common: Hadoop Common contains libraries, utilities, and APIs used by other Hadoop modules. It provides the core functionalities and services that are common to the entire Hadoop ecosystem. These include security, authentication, and communication protocols.
Hadoop Ecosystem Components: Hadoop’s architecture also includes various ecosystem components that extend its capabilities. Some popular ones include:
- Hive: A data warehousing and SQL-like query language for Hadoop.
- Pig: A high-level scripting language for data analysis and transformation.
- HBase: A NoSQL database that provides real-time access to data.
- Spark: An alternative data processing framework known for its speed and in-memory processing capabilities.
- Oozie: A workflow scheduler for managing Hadoop jobs.
- Zookeeper: A distributed coordination service used for maintaining configuration information, naming, and providing distributed synchronization.
Master-Slave Architecture: Hadoop clusters typically follow a master-slave architecture. The master node, known as the NameNode, manages the metadata of the files in HDFS. DataNodes, which run on slave nodes, store and manage the actual data blocks. The Resource Manager is the master node for YARN, while NodeManagers run on slave nodes.
Rack Awareness: Hadoop is aware of the physical location of nodes within the cluster, organized into racks. This awareness helps optimize data processing by reducing network traffic between nodes on different racks.
Hadoop’s distributed architecture allows it to scale horizontally by adding more commodity hardware as needed. This scalability, combined with its fault tolerance and cost-effectiveness, has made Hadoop a popular choice for handling big data in various industries and applications.




{kind=link}
{kind=link}
{kind=link}